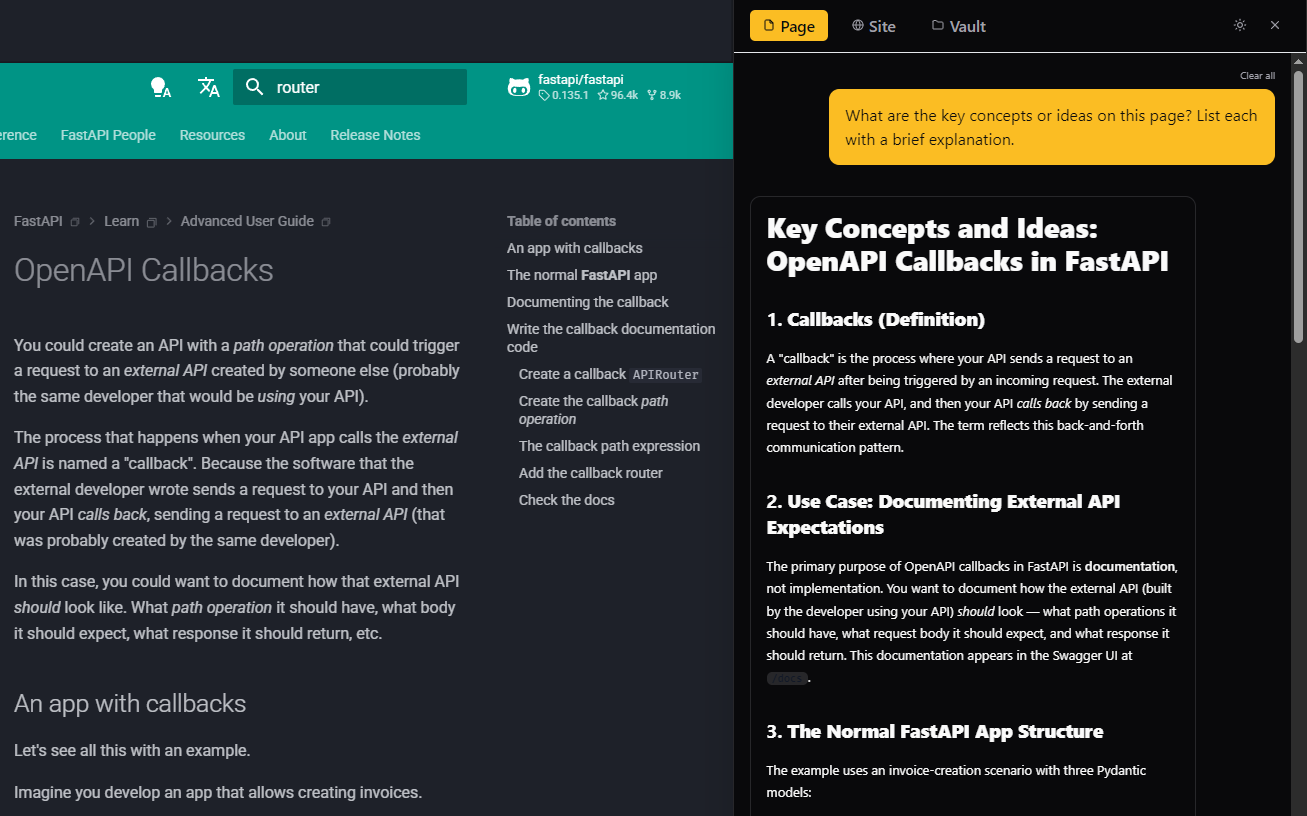
How can I get Daneel today?
Daneel is currently in private Release
Candidate testing — access is by invitation while we finalize the public launch. To request
access, open an issue on our public
GitHub repository telling us a bit about your setup and use case — we'll reach out with a
packaged build.
How much data does the model
download?
The default model is ~600 MB. It downloads once from
Hugging Face's CDN and caches permanently. Smaller models start at ~280 MB.
Does it work offline?
Yes. After the initial model download, all AI
inference runs locally. Querying already-indexed sites works fully offline. Site crawling requires network
access.
Is my data sent anywhere?
No. Page content, questions, and AI responses stay
in your browser. The only network calls: model download (once), optional license refresh (weekly, paid
users), and optional anonymous telemetry (opt-in).
Is the paid license a
subscription?
No. One-time payment of $9. No recurring charges, no
expiration. The license key works forever.
What browsers are supported?
Chrome 113+ with WebGPU. Edge (Chromium-based) works
with sideloading. Without WebGPU, it falls back to CPU inference, or you can connect to Ollama / Claude API.
Why is inference slow on my
machine?
Try a smaller model in Settings. The extension
benchmarks your GPU and recommends a model, but integrated GPUs may struggle with larger models. You can
also connect to a local Ollama server for better performance.