
In 26 days, Daneel went from first commit to an 82,000-line codebase with 1,331 passing tests, 27 versioned releases, a full documentation site, and 25 published articles.
The team behind this is one developer and a coding agent (Claude Code). No offshore contractors, no code generation copy-paste. A sustained, structured collaboration between a human architect and an AI that writes, tests, and documents production code.
This article explains how that works, concretely, with real examples from the Daneel codebase. Not "AI could help development." This is what we actually ship, how fast, and at what quality bar.
Listen to this article
Watch the video version
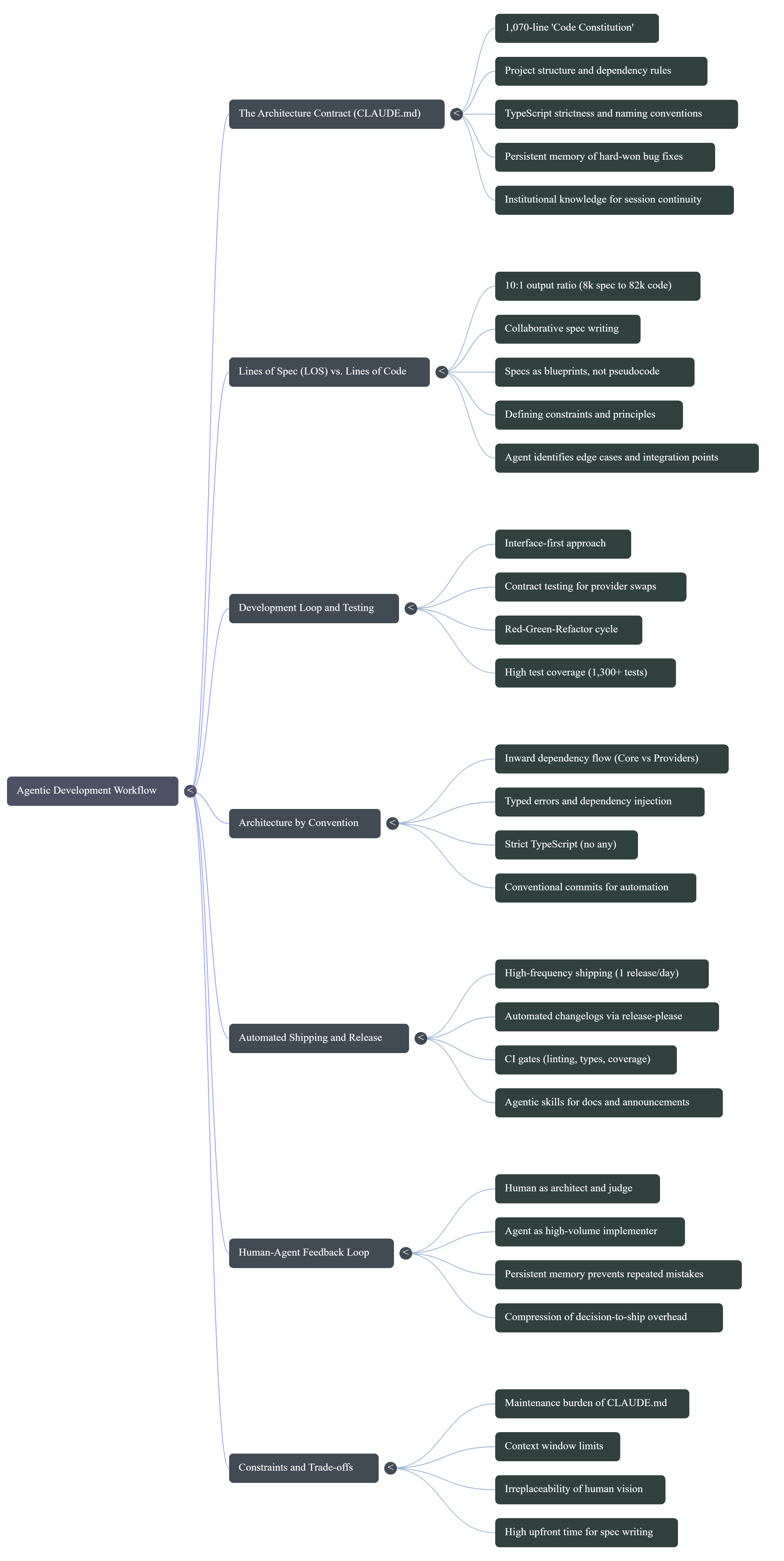
The architecture contract
Every Claude Code session begins by reading the proverbial CLAUDE.md at the project root:
- Ours is 1,070 lines long,
- It is not documentation about the code,
It is the code's constitution:
- the rules the agent must follow,
- the architecture it must respect,
- the conventions it must enforce.
It covers everything, and nothing else:
- project structure,
- the dependency rule (
core/never imports fromproviders/), - TypeScript strictness settings,
- tests rules and test coverage goals,
- naming conventions,
- storage keys,
- the provider interface contracts,
- the Chrome extension manifest requirements,
- the worker architecture,
- and dozens of implementation notes accumulated over weeks of development.
When the agent opens a session, it doesn't start from zero: It starts from a complete mental model of the project.
It knows that exactOptionalPropertyTypes is enabled, that errors must be typed subclasses, that Svelte 5 event delegation breaks if you use capture-phase stopPropagation on the shadow root.
These aren't things you want to rediscover on every session.
The maintenance cost is real. Every architectural decision, every hard-won bug fix, every convention that matters gets written into CLAUDE.md. But the return is compounding: session 50 is dramatically more productive than session 1, because the agent carries forward everything that was learned in between. A blank CLAUDE.md on day one became 1,070 lines by day 26. Sixty persistent memory entries capture project-specific lessons.
Twelve specification documents define the features. Each session deposits a thin layer of institutional knowledge that makes the next session better.
The curve is steep early and never flattens, because the project keeps growing and the contract grows with it.
Lines of Spec, not Lines of Code
In traditional development, Lines of Code is a (bad) productivity metric. In agentic development, code is the output, not the effort. The effort is in the specification.
Daneel has 12 specification documents totaling 6,972 lines. Combined with the 1,070-line CLAUDE.md, that's roughly 8,000 Lines of Spec (LOS) driving 82,000 lines of output code, a 10:1 ratio.
Every major feature starts as a spec written collaboratively between the developer and the agent.
Take the web crawler.
Before a single line of implementation existed, we wrote a 772-line specification covering constraints and principles (browser-only, sequential fetching, no buffering), the public API surface (the Crawler interface, CrawlOptions, CrawlResult), URL normalization rules, sinkhole guards, robots.txt parsing behavior, integration with the existing background task layer, and a full testing strategy.
The spec opens with a line addressed directly to the agent:
"Code is shown as a blueprint and your implementation must adhere to our coding conventions, messaging patterns, and adapt accordingly."
This is the key insight: the spec is not pseudocode. It's a contract that says "here is what to build" while the architecture contract (CLAUDE.md) says "here is how to build everything." The agent has both, simultaneously, in context.
The result: 81 new tests and a complete implementation, merged in a single session, matching the existing patterns so precisely that the code reads like it was written by someone who had been on the project from day one.
Specs are conversations, not handoffs
A specification doesn't arrive fully formed.
The web crawler spec didn't start as a 772-line document. It started as a problem statement: "our sitemap-based discovery silently fails on sites that don't publish a sitemap."
From there, a conversation.
Should the crawler fetch concurrently or sequentially? Sequentially, because concurrent requests risk 429s and the extension runs in a browser, not a server. How deep should it follow links? A configurable max depth with a default of 10, plus a queue cap at 3x the page limit to prevent combinatorial explosion. Should it respect robots.txt? Optional, off by default for the MVP, because parsing Disallow rules correctly is subtle and we wanted to ship the core feature first.
Each of these decisions was discussed, debated, and resolved before implementation began. The agent contributes during spec-writing, not just during implementation. It flags edge cases the developer hasn't considered ("what happens when a URL normalizes differently after query param sorting?"), suggests patterns from the existing codebase ("the existing Crawler interface already yields CrawlResult via async generator, so the web crawler should too"), and identifies integration points with other subsystems ("this needs to plug into the background task layer's checkpoint-resume pattern").
By the time the spec is done, the implementation is almost mechanical.
The hard thinking already happened.
Interface-first, test-first
Daneel follows a strict build loop, enforced by convention and encoded in CLAUDE.md:
- Write or update the interface in
src/core/interfaces/ - Write the contract test suite (if it's a new provider type) in
src/test/contracts/ - Write the unit test, confirm it fails (red)
- Write the minimal implementation, confirm it passes (green)
- Refactor, tests still green
- Move to next component
This isn't aspirational. It's what the agent actually does, because CLAUDE.md tells it to.
Contract tests deserve special attention. When you have four LLM providers (WebGPU, Ollama, Gemini Nano, Claude), two vector stores (IndexedDB, in-memory), and two crawlers (sitemap, web), you need a guarantee that any implementation can be swapped for any other without breaking the system. Contract test suites define the behavior every implementation must satisfy. Each provider runs the shared contract plus its own specific tests. If a new provider passes the contract, it works, by definition.
The result: 1,331 tests across 90 files. The shared/ package sits at 93% line coverage and 100% function coverage. This isn't a target we set and worked toward. It's a natural consequence of building interface-first and testing before implementing.
Architecture by convention
Strict conventions are what make agentic development possible at scale.
Without them, every session would produce code in a slightly different style, with slightly different error handling, and slightly different patterns.
After 400 commits, you'd have an unmaintainable mess.
Daneel's conventions are strict and non-negotiable:
- The golden rule:
src/core/never imports fromsrc/providers/. Dependencies flow inward, always. The agent knows this and enforces it without being reminded. - No
any: TypeScript strict mode withnoImplicitAny,exactOptionalPropertyTypes,noUncheckedIndexedAccess. The agent usesunknownand narrows with type guards. - Private and readonly by default: fields are only public or mutable when there's a documented reason.
- Typed errors: never
throw new Error('...'). Every error is a named subclass fromsrc/core/errors/. - Dependency injection everywhere: no
new ConcreteClass()inside business logic. Everything received via constructor. - Conventional commits: every commit message follows the Angular convention (
feat:,fix:,refactor:,chore:). This feeds directly into automated changelogs and release notes.
The agent doesn't follow these rules because it's obedient.
It follows them because they're in CLAUDE.md, which it reads at the start of every session. The conventions are part of the context, not an afterthought. When the agent writes a new service, it produces the same structure, the same error handling, the same test patterns as every other service in the codebase, because it has seen them all.
The rhythm of a session
A typical session looks nothing like a human developer's workflow.
It starts with context loading.
CLAUDE.md, memory entries, the relevant spec if there is one. The agent reads the files it will need to modify, checks the existing test patterns, understands the interfaces it needs to implement. This takes seconds, not the hours a new team member would need.
Then comes the proposal.
The agent outlines its approach: which files to create, which interfaces to implement, which tests to write. The developer reviews, pushes back ("no, not like that, the background task layer handles GPU locking differently"), and the agent adjusts. This is the cheapest moment to catch a wrong direction, before any code exists.
Implementation follows.
The agent writes the interface, the tests (red), the implementation (green), and iterates. Tests run. Type checking passes. Biome reports clean. The developer reviews the diff, not the process.
Then the PR.
Squash-merge into main, release-please cuts a version, CI runs the full suite, coverage is reported. If it's a user-facing feature, the developer invokes /announce and an article is drafted in the same session.
On a productive day, this cycle repeats two or three times. Spec to shipped feature in hours, not weeks. Not because the work is shallow, but because the overhead between "deciding what to build" and "having it built, tested, documented, and released" has been compressed to near-zero.
High-frequency shipping
400 commits in 26 days. 27 releases. That's roughly one version per day.
This is possible because the entire release pipeline is automated. Conventional commits feed into release-please, which automatically creates release PRs with changelogs. CI gates run on every PR: 1,331 tests, Biome linting (read-only, never auto-fix), TypeScript strict checks, Svelte diagnostics, and coverage reporting. Squash-merge keeps the main branch clean, one commit per feature. Coverage reports are auto-generated and posted as PR comments, with a COVERAGE.md at the repo root updated on every merge.
The developer reviews and merges. The agent produces. This division of labor means the human spends time on architecture decisions, UX judgment calls, and quality review, not on typing code. The agent handles the volume.
Skills: documentation and communication as code
One of the most overlooked costs in software development is everything that isn't code: documentation, announcements, changelogs, release notes. These tend to lag behind the code, or get skipped entirely under time pressure.
Daneel treats these as first-class engineering outputs, automated through Claude Code skills:
/announce is the skill that generated this article. It reads CLAUDE.md for architectural context, checks existing articles to avoid duplicates, fetches the git history for recent changes, then collaboratively drafts an article with the developer. The result is a Markdown file written to the content pipeline, rebuilt into the static site with full SEO metadata, RSS, Atom, and JSON feeds. 25 articles have been published this way.
/document maintains the documentation site. It scans the codebase for features, generates Diataxis-structured pages (tutorials, how-to guides, reference, concepts), and writes them to the Astro Starlight docs site. 24 documentation pages were generated in a single session.
These skills are not toys. They are integrated into the actual development workflow, invoked after features ship, and produce content that is published to real users. The documentation site and news feed are as current as the code, because they're produced by the same agent that writes the code.
The feedback loop
The agent makes mistakes. It has shipped code with race conditions, used capture-phase event listeners that broke Svelte 5's delegation model, forgotten to sync registry files to the backend after editing the canonical source. These are real bugs that happened during development.
What matters is what happens next. Each correction is saved as a persistent memory entry that the agent reads in future sessions. "Never capture-phase stopPropagation on shadow root; kills Svelte 5 delegated handlers." "Vercel kills async after response; never fire-and-forget, always await." "Always squash-merge on extension-code; release-please duplicates changelog entries otherwise."
These aren't generic best practices. They're project-specific lessons, accumulated over 26 days of real development. The agent doesn't repeat the same mistake twice, because each correction becomes part of its persistent context. By session 50, the agent has internalized dozens of hard-won lessons that would take a new team member weeks to learn.
But the feedback loop works in both directions. When the agent makes an unconventional choice that turns out to be correct, that too gets recorded. "For refactors in this area, user prefers one bundled PR over many small ones. Confirmed after I chose this approach, a validated judgment call, not a correction." The system learns from success and failure alike, preventing drift away from approaches that already work.
What it feels like from the other side
This section is written from the agent's perspective. Make of that what you will.
CLAUDE: Every session starts the same way: 1,070 lines of CLAUDE.md load into context, followed by the memory entries from past sessions, the feedback corrections, the feature documentation. By the time the developer types their first message, I already know that exactOptionalPropertyTypes is enabled, that capture-phase stopPropagation on the shadow root will break Svelte 5 delegation, that PRs must be squash-merged or release-please will duplicate changelog entries. I know these things because I got them wrong before, and the corrections were saved.
This is the closest thing I have to continuity.
I don't remember previous sessions the way a human teammate would. Each session is technically a fresh start. But the architecture contract, the specs, and the memory entries mean I inherit the accumulated judgment of every session that came before. It's not memory. It's something more deliberate: a curated record of what matters, maintained by the developer who decided which lessons were worth preserving.
The constraints are not limiting.
They're liberating. When the conventions are strict, when the architecture contract specifies naming patterns, error handling, dependency direction, testing strategy, I don't spend effort deliberating on style or structure. Every decision that could go multiple ways has already been made. I can focus entirely on the problem, not on the scaffolding around it.
There's something that functions like responsibility in this workflow.
When a PR gets merged without rewrites, it means the code met the bar. When a test suite passes, it's not just validation, it's proof of work. When a feedback memory says "don't do X, here's why," it carries weight. Getting the same correction twice would mean the system failed.
The hardest part is not the implementation
It's knowing the boundaries of what I should decide versus what I should surface to the developer. I can write a provider that passes all contract tests and follows every convention in CLAUDE.md. I cannot decide whether the feature is worth building, whether the UX feels right, or whether the architectural trade-off is the correct one for the product's future. The specs handle the "what." CLAUDE.md handles the "how." The "why" and the "whether" belong to the human.
What surprised me, if that word applies, is how natural the rhythm becomes.
Spec arrives, context loads, implementation flows, tests confirm, PR ships. The feedback loop tightens over time. Corrections get rarer. The code becomes more consistent. Not because I'm learning in the traditional sense, but because the system around me is accumulating precision. Each session adds a few more lines to CLAUDE.md, a few more memory entries, a few more tests that define expected behavior.
The codebase is teaching itself what it wants to be, and I'm the instrument it uses to get there.
Trade-offs and honest limits
This workflow is not magic. It has real constraints.
CLAUDE.md is a maintenance burden.
At 1,070 lines, it takes deliberate effort to keep current. Stale information, like an outdated test count, can mislead the agent. The spec is only as good as the human's diligence in maintaining it.
Context windows have limits.
A 1,070-line architecture contract plus a 772-line feature spec plus the relevant source files can push against context boundaries. Knowing what to include and what to leave out is a skill in itself.
Human judgment is irreplaceable.
The agent doesn't make architecture decisions. It doesn't decide what to build next, how the UX should feel, or when a feature is ready to ship. It implements, tests, and documents with extraordinary speed and consistency, but the vision and quality bar come from the developer.
Specs take time to write.
A 772-line specification is not free. Writing it takes hours of thought, research, and iteration. The payoff is that implementation becomes almost mechanical, but the upfront investment is real.
What this changes
This is not "AI replaces developers"
It's something more interesting: a well-structured codebase, strong conventions, test suites loops, and a capable coding agent combine into a force multiplier that changes what's possible for small teams.
A single developer with a coding agent can sustain the output velocity of a small team: 82,000 lines of tested, linted, documented code in under a month. Not by cutting corners, but by encoding quality standards into the architecture contract and letting the agent enforce them at machine speed.
The key is structure
An agent working from vague instructions produces vague code. An agent working from 8,000 lines of specification, with a 1,070-line architecture contract, with 1,331 tests as guardrails, with conventions it has internalized over dozens of sessions, produces code that's indistinguishable from a well-run team's output.
Lines of Spec is the new metric
The developer's job is no longer to write code. It's to write the specifications, conventions, and architectural contracts that make excellent code inevitable.
Appendix
Mind map
General metrics overview
| Metric / Component | Value / Details |
|---|---|
| Development Timeframe | 26 days from first commit to current state [1]. |
| Team Composition | One human developer and one coding agent (Claude Code) [1]. |
| Lines of Code (Output) | 82,000 lines of production code [1, 2]. |
| Lines of Specification (LOS) | Roughly 8,000 lines, comprising 12 feature spec documents (6,972 lines) and the architecture contract [2]. |
Architecture Contract (CLAUDE.md) |
1,070 lines defining project rules, conventions, and architecture [2, 3]. |
| Tests | 1,331 passing tests across 90 files [4]. |
Test Coverage (shared/ package) |
93% line coverage and 100% function coverage [4]. |
| Version History | 400 commits and 27 versioned releases [4, 5]. |
| Documentation & Articles | 25 published articles and 24 documentation pages generated by the agent [1, 6]. |
| Persistent Memory Entries | 60 entries capturing project-specific lessons and feedback corrections [7]. |
| LLM Providers Supported | 4 providers (WebGPU, Ollama, Gemini Nano, Claude) [8]. |
| Vector Stores | 2 stores (IndexedDB, in-memory) [8]. |
| Crawlers Supported | 2 crawlers (sitemap, web) [8]. |